A complete walkthrough of the OmniTacTune pipeline and all four contact-rich tasks.
Four Contact-Rich Tasks
10×
Peg-in-Hole
Spatial Generalization + Insertion
10×
Charger Insertion
Precise Insertion
10×
Cap Opening
Tool Using + Precise Interaction
10×
Box Opening
Tool Using + Dynamic Pivoting
Training Demonstration
A one-take demo of online real-world RL — the policy is trained in ~40 minutes directly on hardware, with no resets staged for the camera.
One-Take Online RL — Trained in 40 min
Continuous real-world practice from a weak base policy to reliable contact-rich behavior.
Generalize Across Different Base Policies
The same residual adaptation pipeline plugs into visual base policies that differ in observations, data sources, architectures, and action-chunk horizons.
Flow Policy
ACT
Diffusion Policy (DP)
π0.5
Generalize Across Different Data Sources
Visual base policies can be learned from scalable human videos or from robot teleoperation.
3×
Human Video
Cross-embodiment motion priors from human demonstrations
10×
Teleoperation Data
VR-teleoperated robot demonstrations
Motivation
Insights
1
Visual data is abundant, and the visual policies trained on it are strong — but vision alone struggles with contact-rich manipulation, where success hinges on local force and contact geometry that cameras cannot measure.
2
Tactile data is highly informative for contact, yet it is far harder to collect than visual data and tends to waste the abundant visual data already available if you try to scale it from scratch.
3
We want an efficient, generalizable, and robust pipeline that adds tactile feedback on top of an existing visual policy — rather than retraining a visuo-tactile policy from scratch.
4
Inspired by how humans learn: after acquiring a visual prior through imitation, we use online practice — interacting with the world through touch — to learn the contact strategy that completes the task.
Vision and touch play complementary roles. Vision provides broad, scalable supervision for task-level behavior; touch provides local, residual feedback for the last mile of physical interaction.
Overview
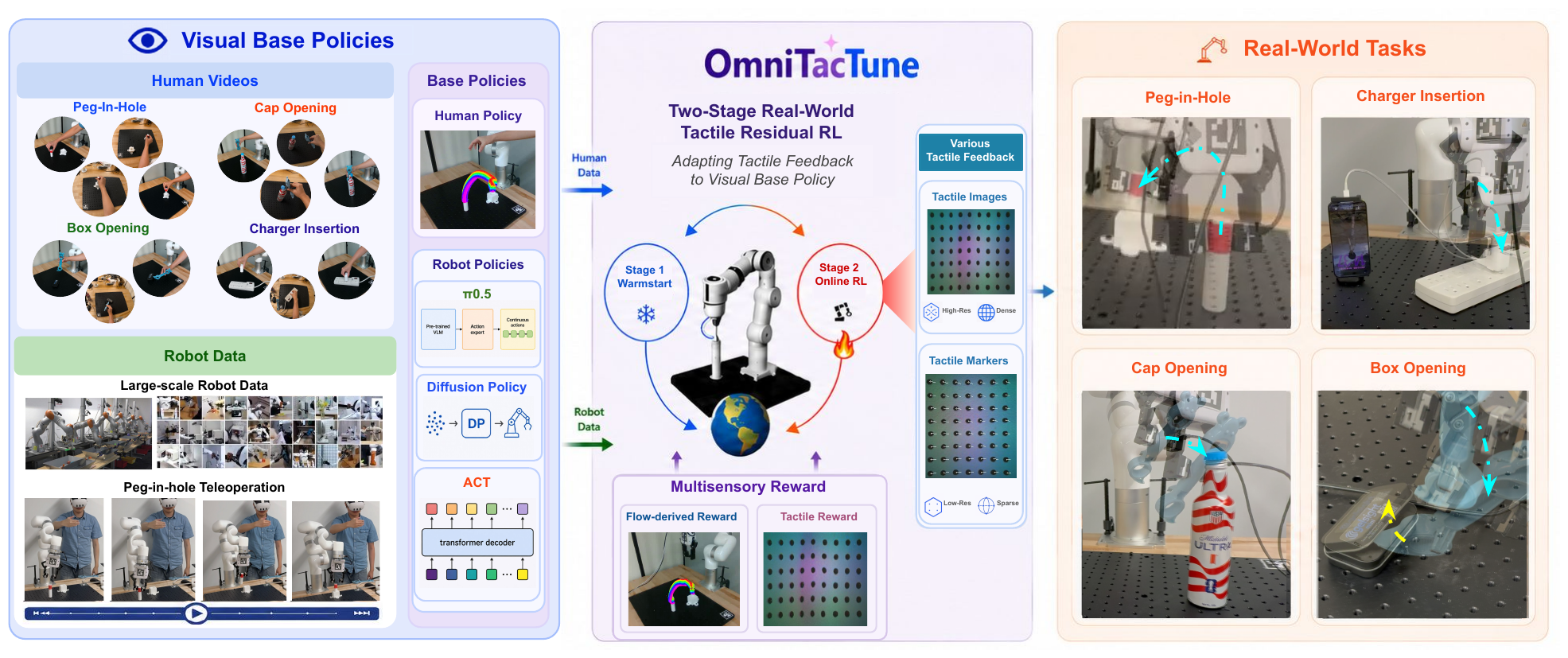
What is OmniTacTune?
OmniTacTune is a policy-agnostic real-world RL pipeline that adapts tactile feedback to pretrained visual policies through residual correction. It keeps the visual policy frozen as a motion prior and learns a lightweight tactile residual that fixes the contact-rich last mile — generalizing across diverse tasks, base policies, and tactile representations.
OmniTacTune adapts tactile feedback to diverse visual base policies trained from human videos or robot data (left) through a two-stage real-world tactile residual RL pipeline (middle), enabling efficient tactile adaptation across challenging contact-rich manipulation tasks (right).
Abstract
Abstract
Visual policies learned from human videos, teleoperation, and robot demonstrations offer scalable motion priors, but often fail in contact-rich manipulation, where success significantly depends on local force and contact geometry. Tactile sensing provides these complementary signals, yet tactile data remain costly to collect and hard to generalize across sensors, robots, and tasks. We introduce OmniTacTune, a policy-agnostic real-world RL pipeline that adapts tactile feedback to pretrained visual policies through residual correction. OmniTacTune uses a two-stage design: it first bootstraps tactile-aware learning from autonomous base-policy rollouts, then learns a lightweight tactile residual policy through online interaction. Extensive experiments show that OmniTacTune generalizes across diverse contact-rich tasks, visual base policies, and tactile representations. Across four real-world contact-rich tasks, it improves visual base policies from 5–40% success to 85–100% within 40–80 minutes, demonstrating an efficient path for adapting tactile feedback to scalable visual robot policies.
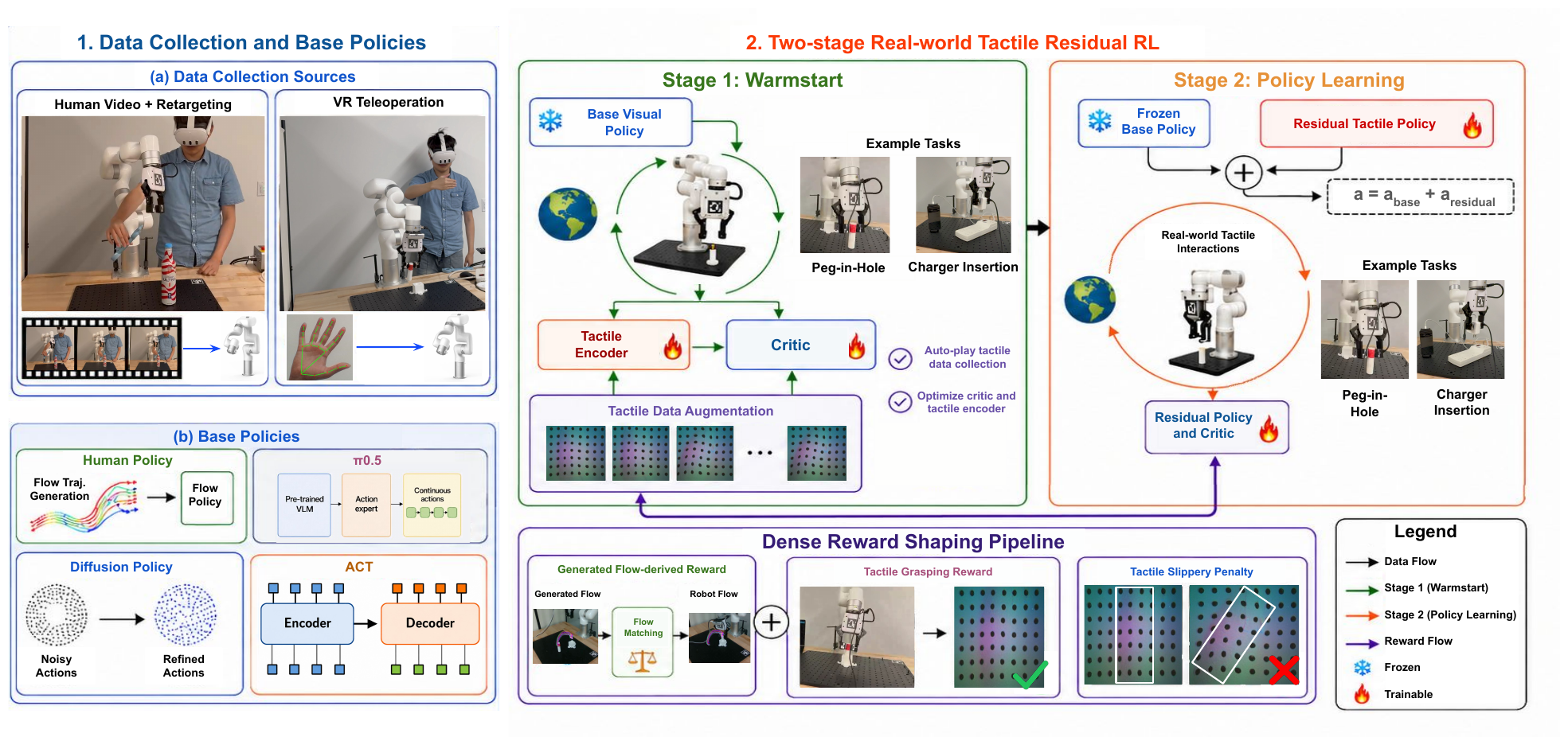
Method
Two-StageReal-World Tactile Residual RL
Implementation Challenges:
adapting a new tactile modality to a frozen visual policy is difficult because
visual demonstrations don't provide offline tactile interaction data
for replay buffer and critic initialization. Moreover, off-the-shelf
tactile encoders are not directly reliable under task-specific contact distributions.
Stage 1 — Tactile-Aware Bootstrapping:
autonomous rollouts of the frozen base policy initialize the
replay buffer, bootstrap a
flow-tactile critic, and adapt the
tactile encoder using
ControlTac augmentation.
Stage 2 — Online RL:
a lightweight flow-tactile residual policy learns
contact-aware corrections on top of the
frozen visual policy, guided by an
object-centric multi-sensory reward.
System overview. OmniTacTune collects visual demonstrations via human-video retargeting and VR teleoperation to train diverse base policies (left), then adapts tactile feedback through a tactile-aware bootstrapping stage and an online residual-learning stage (top right), using a dense multi-sensory reward to guide efficient real-world learning (bottom).
Flow Generation
Generated Flow for Policy Guidance and Reward Shaping
OmniTacTune generates object-centric flow from the initial observation to provide two complementary signals: motion guidance for both the base policy and the residual policy, and a dense flow-derived reward during residual RL. This generated task-level guidance encourages smoother object-centric trajectories while making real-world training more efficient and reliable.
Peg-in-HoleSpatial Generalization
Charger Insertion
Guidance + reward shaping
Cap Opening
Guidance + reward shaping
Box Opening
Guidance + reward shaping
How Generated Flow Makes Residual RL Policy-Agnostic
Any Frozen Visual Policy
Human-flow policy, ACT, DP, or π0.5 outputs a base action chunk
→
Shared Object-Centric Interface
generated keypoint goals + base-policy action chunk plus tactile feedback, no hidden states
→
Flow-Tactile Residual Policy
predicts bounded contact correction Δares only when correction is needed
updates residual policy, critic, and tactile encoder while keeping the base policy frozen
Policy-Agnostic Residual Policy
The key question is how one residual actor can correct architecturally diverse visual policies. OmniTacTune addresses this through interface-level agnosticism: the residual actor avoids policy-specific hidden states, visual tokens, or network internals.
Instead, it uses two policy-independent inputs: generated keypoint goals for shared task-level guidance, and the base-policy action chunk for short-horizon motion intent. Together with tactile feedback, this common interface enables closed-loop correction without finetuning the frozen visual policy.
Object-Centric Reward Shaping
The reward is also independent of the base policy. Instead of rewarding a particular policy representation, OmniTacTune computes dense feedback from task geometry, generated flow, tactile contact, and safety constraints. This lets the same reward train residual RL across different policies and tasks.
At a high level, the reward guides the robot toward the object, encourages stable grasp/contact, and matches observed object motion to the generated object-centric flow. Tactile terms penalize slip or unsafe contact, while a terminal success reward anchors dense shaping to the actual task objective.
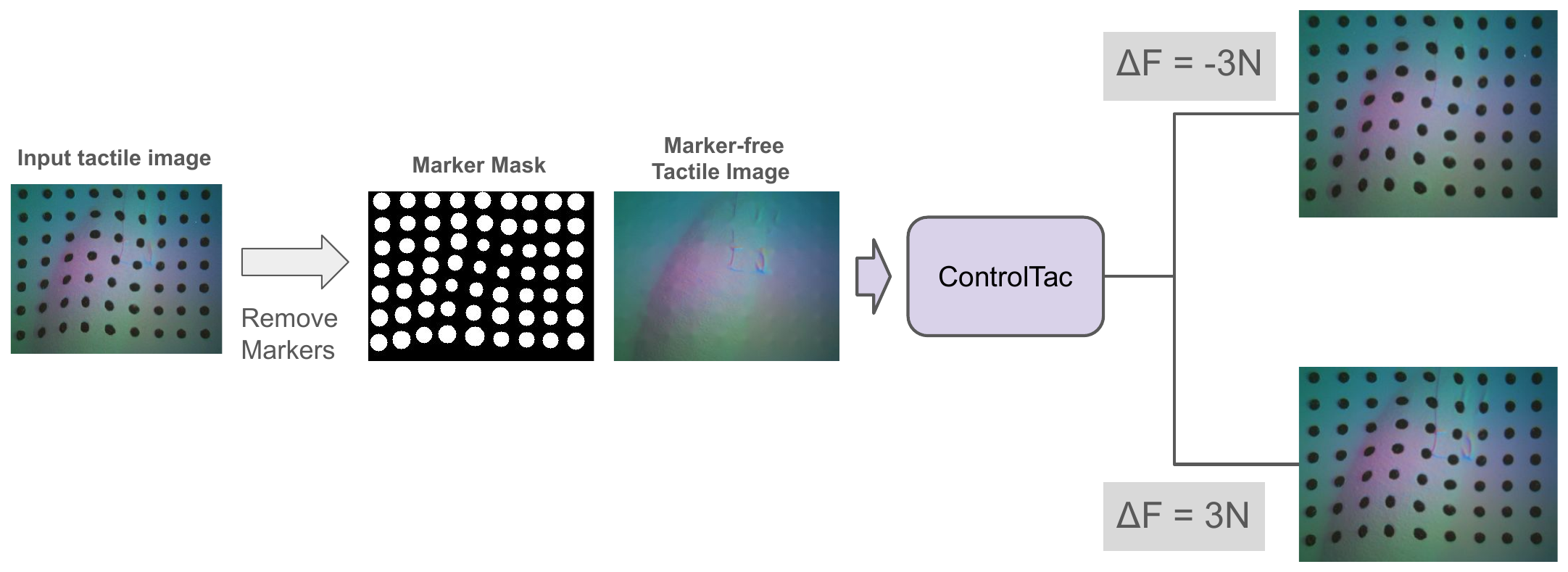
Tactile Data Augmentation
ControlTac Augmentation for Tactile-Aware Bootstrapping
Because the bootstrapping buffer holds only a few real contact pairs, we use ControlTac to expand tactile diversity without any extra robot interaction. We first remove the marker pattern from a real tactile image to obtain a marker-free reference, generate new tactile images under different contact forces (ΔF), and then composite the original markers back. Robot states, actions, flow features, and rewards stay unchanged — only the tactile images vary — exposing the encoder and critic to richer contact-forces.
ControlTac trajectory-level augmentation. A real tactile image is converted to a marker-free reference, perturbed to new contact forces (e.g. ΔF = −3N and ΔF = +3N) via ControlTac, and recomposed with the original marker mask — producing physically plausible tactile variants for tactile-aware bootstrapping.
Experiments
Results
Efficient Tactile Adaptation with Real-World RL
Across all four tasks, OmniTacTune adapts tactile feedback faster and more reliably than prior real-world RL methods, lifting weak base policies to 85–100% success within 40–80 minutes of online practice.
Training efficiency. OmniTacTune improves from 5–40% to 80–100% within 40–80 minutes and consistently exceeds all baselines.
Table 1. Final success rates across the four real-world contact-rich tasks after RL training. OmniTacTune reaches a 93.75% average, far above PLD* (52.5%), PLD Visual-Only (37.5%), and ViTAL (43.75%).
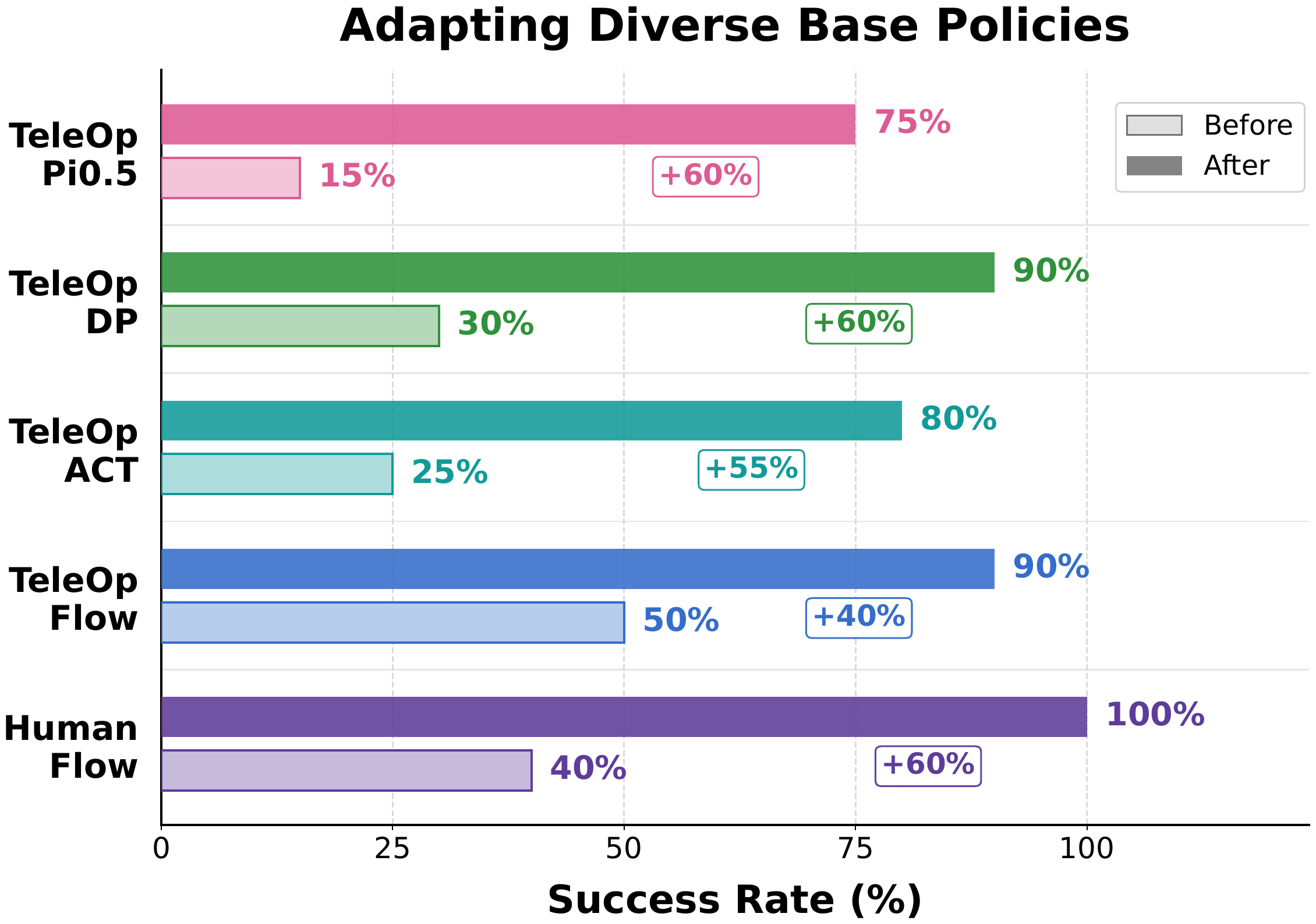
One Residual Learner, Many Visual Policies
The residual pipeline is not tied to a specific policy architecture. On Peg-in-Hole, OmniTacTune improves five different base policies with different observations, data sources, architectures, and action chunks — within ~50 minutes of real-world practice.
It lifts every base policy by +40% to +60% success, reaching 75–100%. The human flow policy yields the smoothest motion prior and the highest final performance.
Flow +40–60%ACT +55%DP +60%π0.5 +60%
OmniTacTune consistently improves diverse base visual policies on Peg-in-Hole.
Online Tactile Practice Beats More Demonstrations
Online tactile residual refinement beats learning a visuo-tactile policy from more demonstrations — even when every imitation baseline is given an extra 50 minutes of teleoperation data.
Table 2. Success rates of visuo-tactile robot-learning methods on Peg-in-Hole. To ensure a fair comparison, all baselines were given an additional 50 minutes of teleoperation data (demonstrations increased from 50 to 90) — matching the budget of our online stage. Even so, imitation- and SFT-based visuo-tactile learning remains 20–30% behind OmniTacTune, showing that contact correction is better learned through trial-and-error than from extra tactile demonstrations.
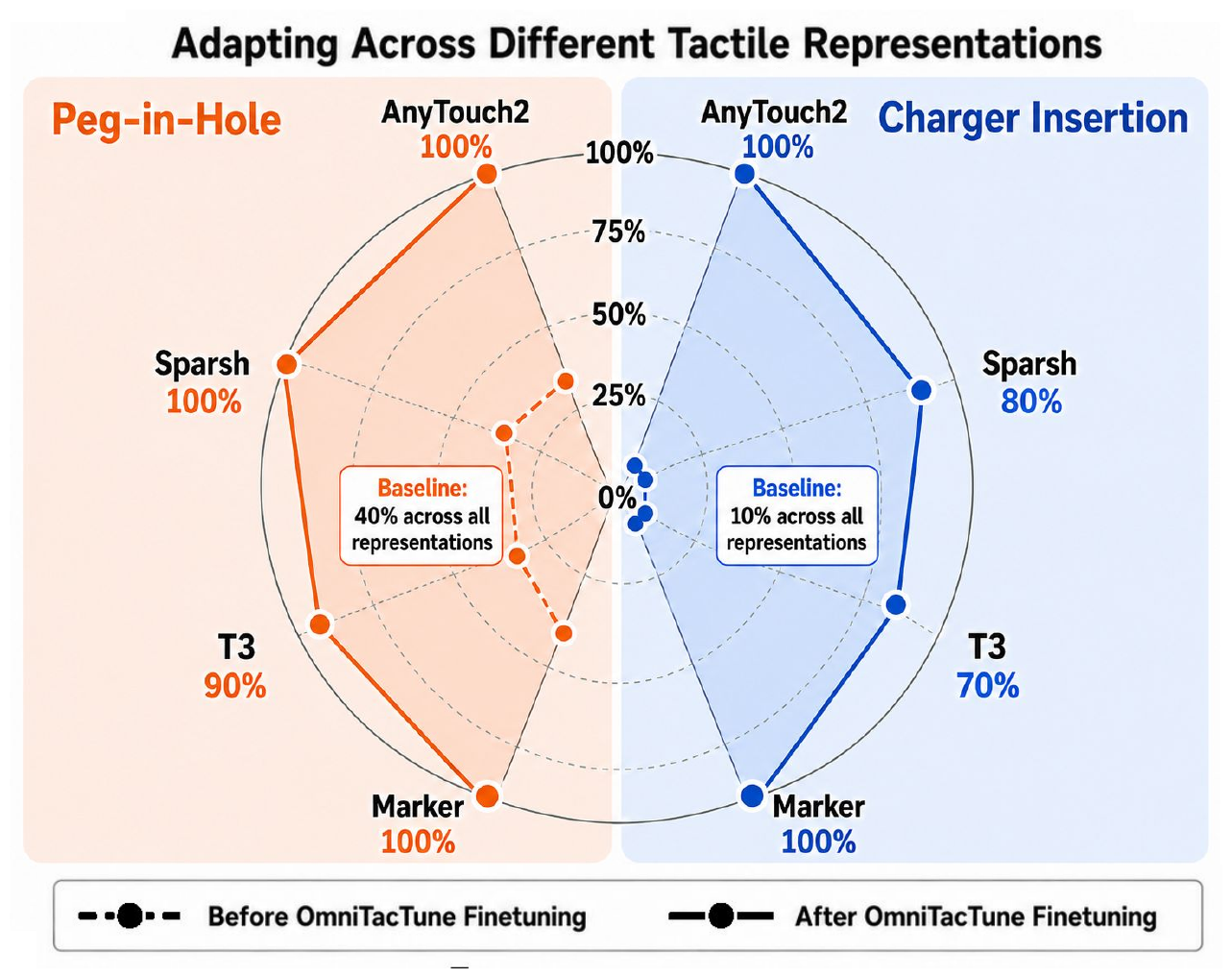
One Pipeline, Many Tactile Representations
OmniTacTune is not tied to a particular tactile representation. On Peg-in-Hole and Charger Insertion, it adapts equally well with pretrained tactile image encoders (AnyTouch2, Sparsh, T3) and with compact low-dimensional tactile markers.
AnyTouch2 and markers reach comparable final performance, while T3 and Sparsh lag slightly on the more dynamic Charger Insertion — likely because they are not pretrained on dynamic-contact tactile data.
AnyTouch2MarkersSparshT3
Adapting different tactile representations via OmniTacTune on two contact-rich tasks.
Analysis
Ablation Studies
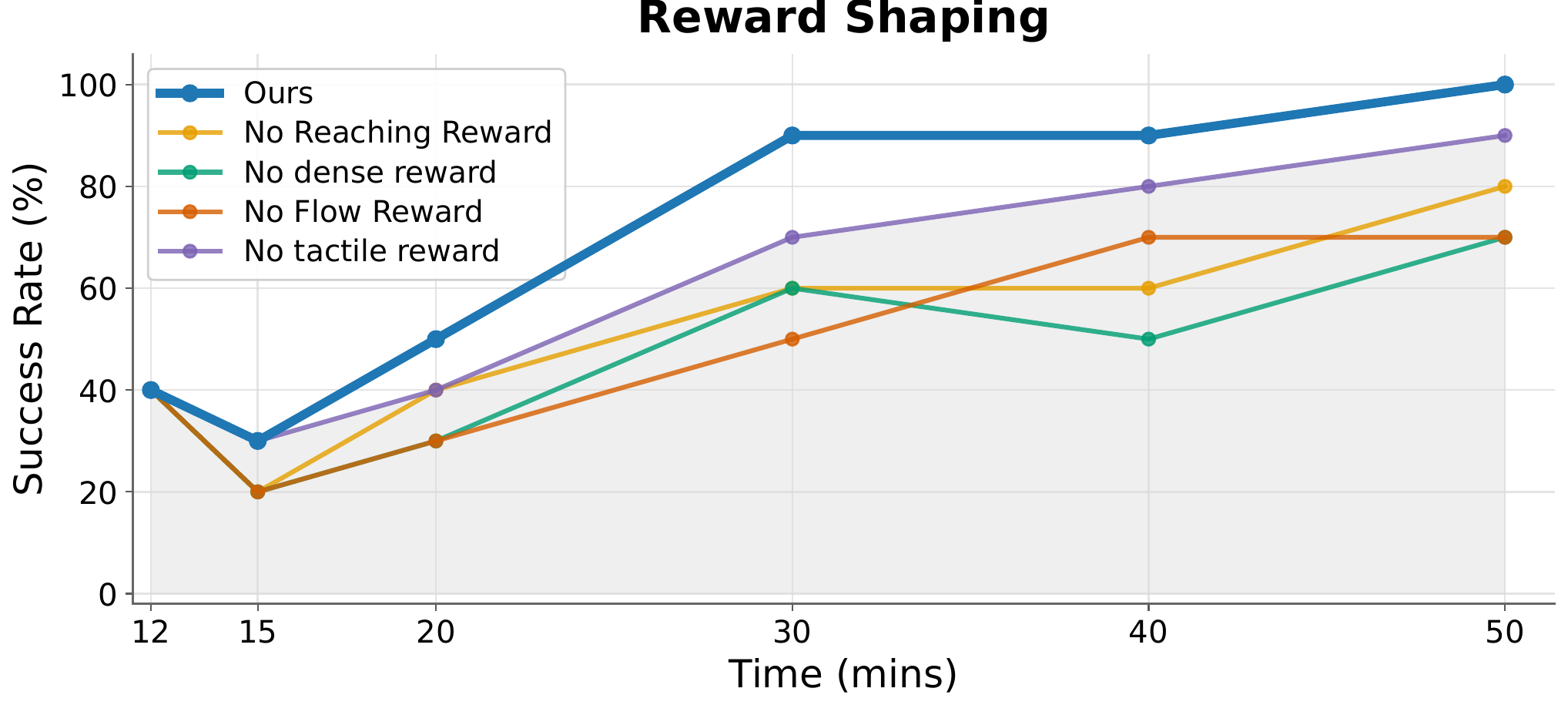
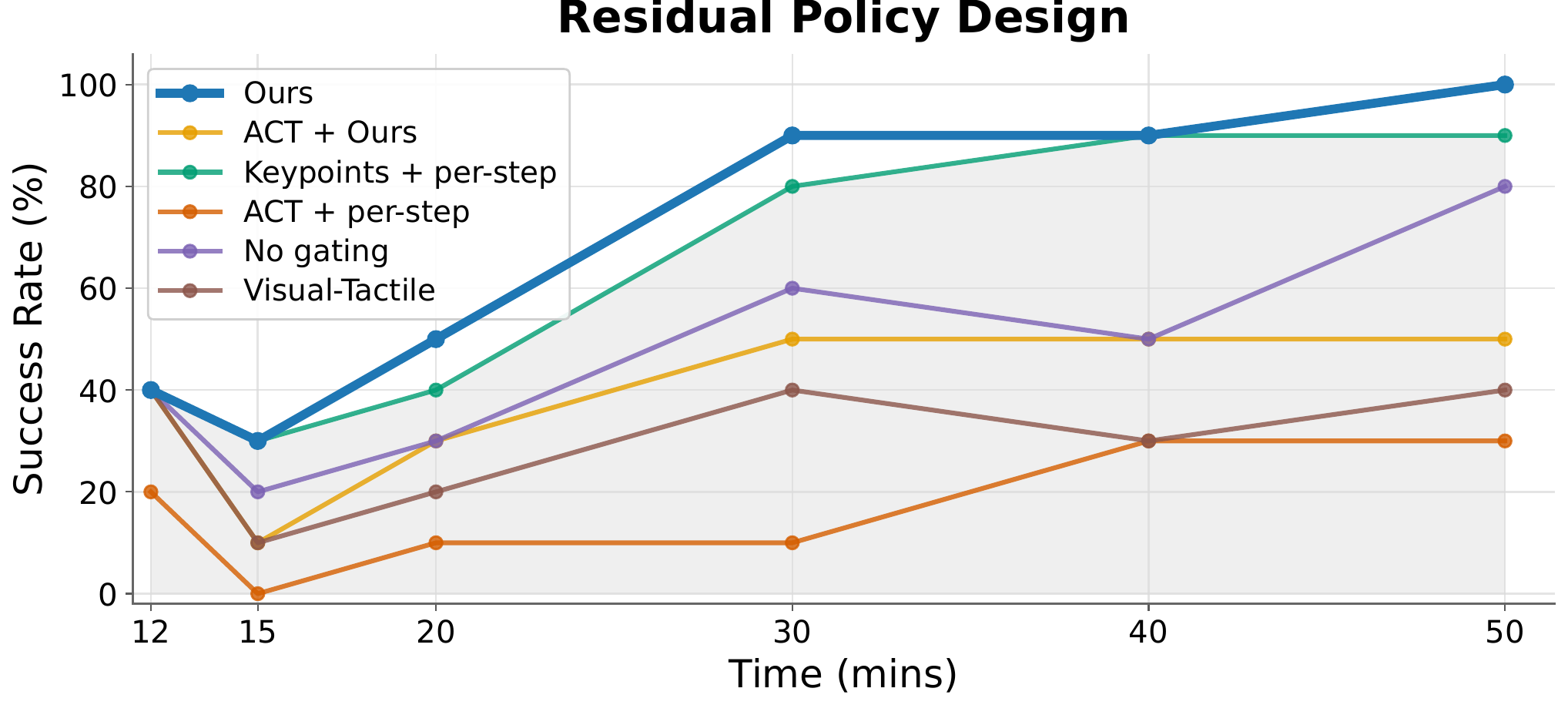
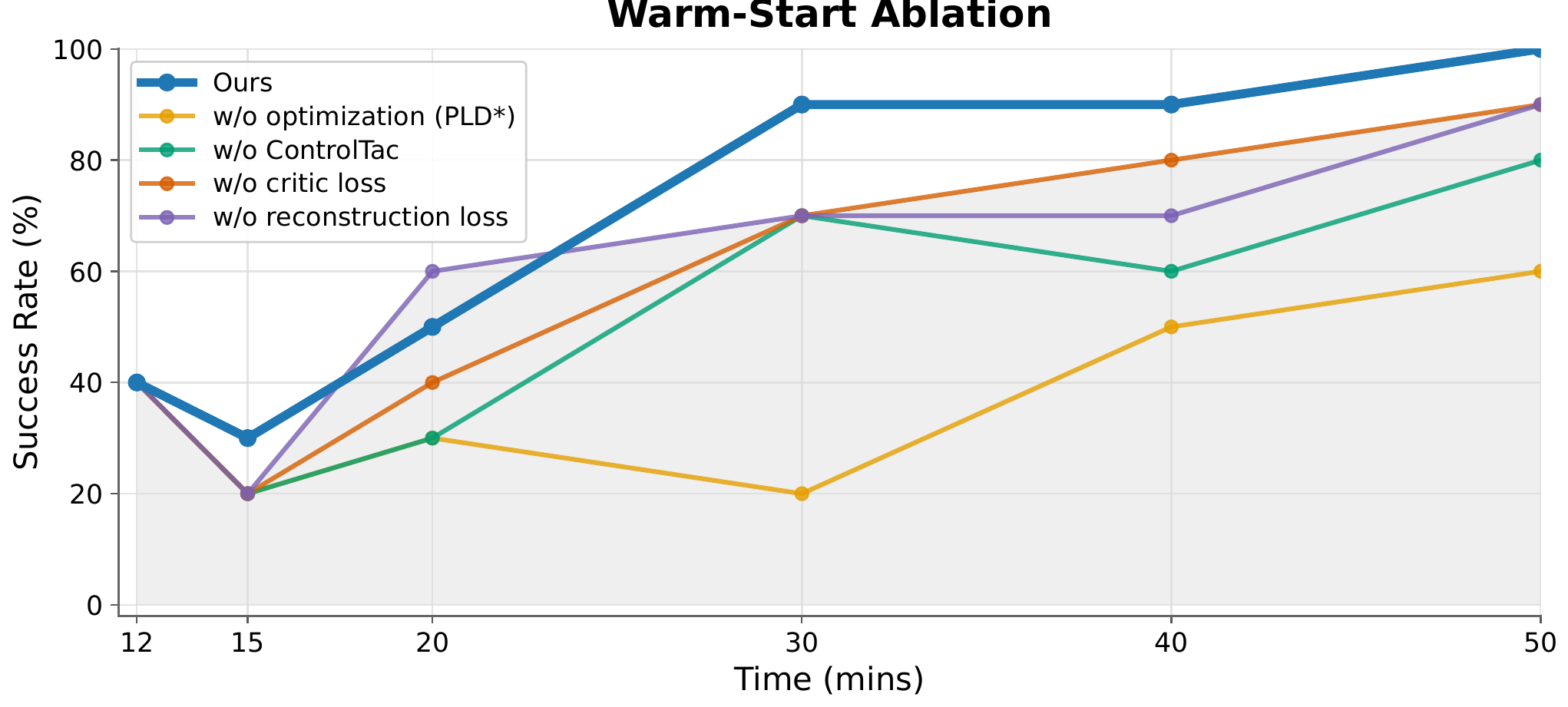
We ablate the four core design choices of OmniTacTune on Peg-in-Hole. Each component contributes to faster, more stable adaptation.
Reward Shaping
Removing any component of the multi-sensory reward slows learning and lowers final success — reaching, dense flow, and tactile rewards are all needed.
Residual Policy Design
Trajectory-level keypoint guidance with contact-aware gating outperforms per-step keypoints and raw visuo-tactile conditioning.
Bootstrapping Strategy
Optimizing the tactile encoder + critic (with ControlTac augmentation) during bootstrapping is critical for stable residual RL.
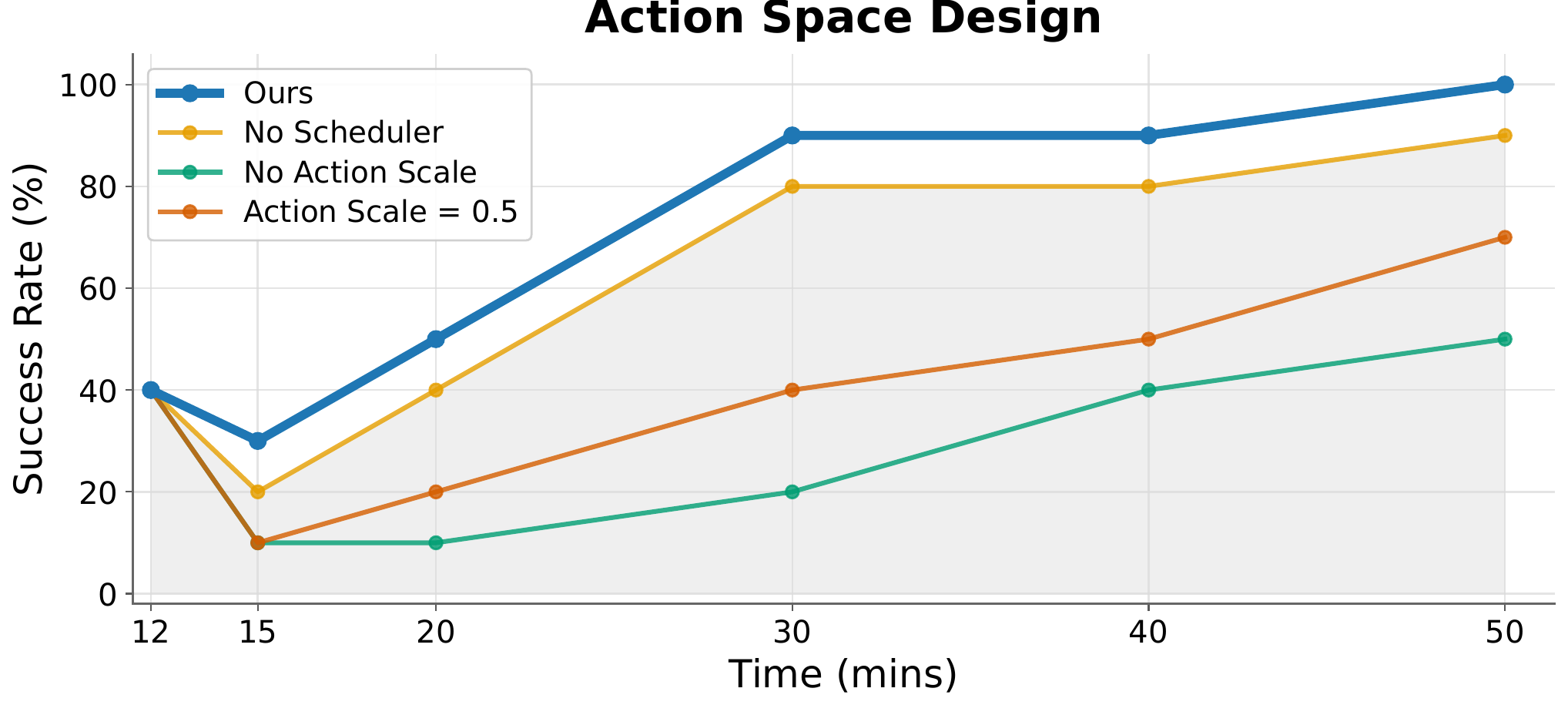
Action Space Design
Both the residual scheduler and action scaling matter; an appropriate scale (0–0.15) keeps exploration stable and sample-efficient.
Citation
BibTeX
@misc{yu2026omnitactunepolicyagnosticrealworldrl,
title = {OmniTacTune: Policy-Agnostic Real-World RL for Tactile Residual Adaptation of Visual Policies},
author = {Kelin Yu and Haode Zhang and Harish Ravichandar and Yunhai Han and Ruohan Gao},
year = {2026},
eprint = {2607.03723},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2607.03723},
}
 OmniTacTune:
OmniTacTune: